
Handling 780k GitHub events per day
A year ago, we wrote about our workload issues and how we were handling 300k GitHub events per day. Our main challenge was avoiding GitHub rate limit and quota system while delivering service with low latency and high throughput.

Earlier this year we noticed more and more issues handling our traffic. We grew to receiving 780k GitHhub events per day. While our system perfectly respected GitHub quota and rate limits, some users complained that our engine had a high latency in certain cases.
We monitor every part of our engine, including the event processing latency. The graph below shows how old are the events processed by Mergify.
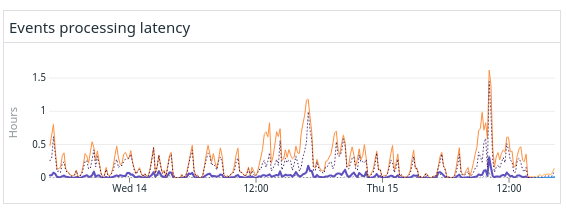
While the purple line showing the average latency time was correct, the orange line in the graph above shows that the maximum latency time could be huge. The worst-case for those couple of days was the engine treating an event 1 hour and a half after it received it.
Offering a feedback loop of 90 minutes was not part of our plan.
We spend quite some time dissecting our engine internals to understand what would happen here until we realized the source was one of our features: conflict detection.
Conflict Detection
Mergify offers conflict detection in pull requests conditions with the conflict attribute. However, this is a tricky attribute to match a pull request for.
Indeed, most pull request attributes change when the pull request itself changes. For example, if you add a label to a pull request, the impact is restricted to that pull request. GitHub sends an event that indicates the pull request label changes. The engine just needs to refresh this pull request and that's it. Simple and fast.
However, when you merge a pull request, this can introduce a conflict between the base branch and any of the pull requests targeting this branch. In that case, GitHub sends a special push event that means a branch has changed. For Mergify, this means any pull request targeting this branch needs to be refreshed.
And there could be dozens. Even hundreds. 😨
And this would happen for each new merge done to any base branch. 😥
Up to now, the way the system worked was pretty naive: Mergify engine would refresh every pull request affected, consuming tons of GitHub requests, drying out the quota for repositories with a large number of pull requests, and blocking the rest of the work to do for minutes — if not hours. This is the latency issue that some users started to notice as their backlog of open pull requests grew.
Optimizing
Our first optimization idea was to only trigger the conflict detection code if the repository uses the conflict conditions in its rules. While this would work, it would have been a little bit cumbersome to implement and would only benefit to a low number of repositories. It would also need to be maintained: if any condition would show the same behavior as the conflict attribute, we would have to take this into consideration and think about special-casing it too.
We decided to not take that route and looked for another option.
Our second idea was to actually implement a prioritization system for pull requests. The concept is quite simple: pick the list of pull requests that need to be processed, start with the important (active) ones, and finish with the one that might need a refresh because of a potential conflict.
This would also work well, except that processing all the lower priority pull requests can still take a lot of time, blocking the processing of the newly active pull requests. Reaching a maximum throughput for active pull requests with this implementation would not have been possible, leaving repositories with a lot of activity with still a high latency. 😢
Redesigning Storage Layout
We were pretty sure we needed to handle something along with priorities in the resulting algorithm, but any solution we came up with was actually limited by the existing storage layout.
Giving priorities to GitHub events was the right idea for this performance problem, as detecting conflict on a stale pull request doesn't really help developers. Engineers want quick feedback on what they are currently working on, not immediate feedback on that old pull request they forgot about.
The way the engine architecture worked so far was by reading events and treating them all at the same time for a single organization. Once it started processing events for an organization, even if it ordered the pull requests, there was no way for it to stop processing non-urgent events.
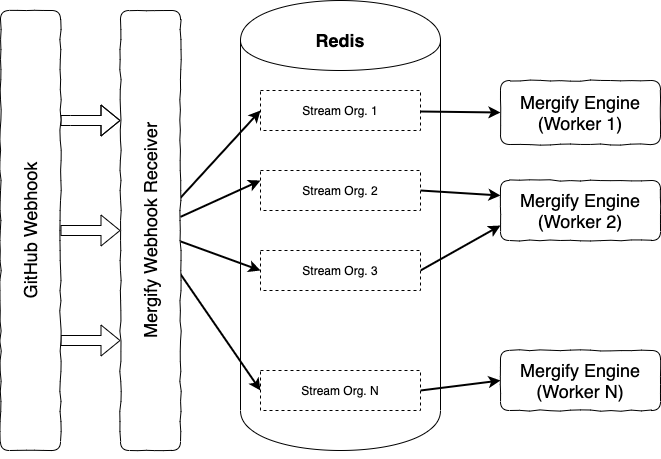
In order to be able to break an evaluation cycle, we needed a finer granularity in the processing of events. Distributing all organizations events in a stream per pull requests was the next logical granularity split to make, therefore we went that way.
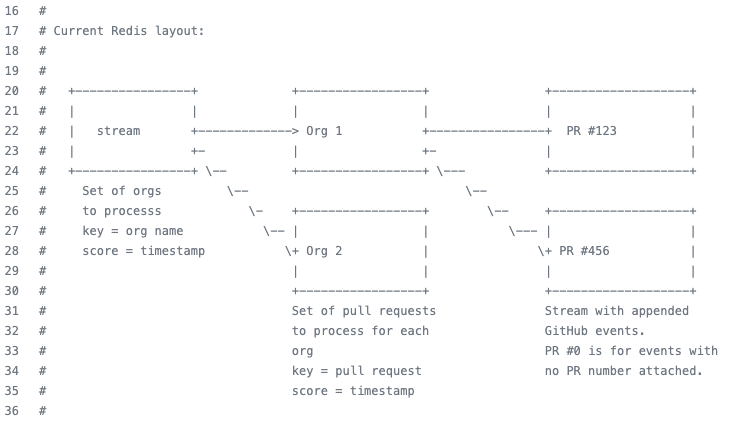
Doing more triage upfront, and using a Redis stream per pull request rather than per organization, gave us the granularity needed to organize and sort the pull requests by priority. Each pull requests is now scored and processed in the right order of priority.
The engine reads the full list of pull requests to process, and process then one at a time in order of importance.
If there's a lot of pull requests, the engine will automatically preempt itself after 30 seconds of processing a single organization. This is mean to be sure that it does not spent too much time processing inactive pull requests, in the event that new activities was detected on pull requests. The engine makes sure to go back reading the list of pull requests that needs processing, starting with active and high-priority ones.
Measuring Impact
We are hard believer on observability, and we rely a lot on Datadog to monitor our application. We added metrics and traces to makes sure that our algorithm worked and was behaving as expected in production.
After a few hours of monitoring, we saw that no organization processing was taking often less than 13s for ¾ of the processing. The rest could take as long as 30 seconds, but not much more, as it would be preempted to make sure nothing is stuck processing old pull requests.

The overall maximum latency for events can still be quite high, but it is now only on inactive pull request, which does not impact the feedback loop and makes software engineers happy!

