
Handling 300k GitHub events per day
As Mergify is a pull request automation tool, to execute actions on your pull requests, it needs to be aware of any change done on them. To get notified of any mutation, Mergify relies on the GitHub App webhook mechanism. That means that on any modification done to a pull request, GitHub sends an event to the Mergify engine, which then needs to handle it.
The Naive Approach
Mergify engine is written in Python. Until a few weeks ago, it was using a pretty simple workflow to handle those events:
- Events were received over HTTP by a Flask application.
- The application would push them to a Celery task queue.
Celery was configured to store tasks in Redis to ensure the engine would never lose any GitHub events. This was particularly important since we didn't want users to be impacted by any maintenance and wondering why the engine wouldn't be triggered.
Then, the Celery workers were in charge of executing the rules evaluator and run the associated actions for each GitHub event. If any unexpected issue occurred (e.g., connectivity issue, GitHub outage, GitHub API rate limit hit…), the task was kept into Redis, and the Celery worker retried it automatically after a while. Celery was configured to handle hundreds of events in parallel to maximize engine throughput.
This setup worked very well for a while. Though, one day…
Rate Limit and Abuse
Among other things, we monitor HTTP requests and tasks. We instrumented many custom metrics that we send to Datadog using their statsd protocol. That allows us to watch if everything goes well in our application.
One day, we started to see a rise of GitHub API calls returning the HTTP code 403. A quick look in our logs showed that many requests were triggering the GitHub abuse and rate limit mechanism.
Rate Limit
GitHub maintains a rate limit for each organization. That rate limit is reset every hour; if the engine ever this that rate limit, it'd store events until the hour passed to try again. While this strategy worked well, it increases a lot the delay between user interactions and the Mergify engine result.
As a result, people thought our engine was not dysfunctional and laggy, while it was just waiting for its permission to use GitHub API again. Sigh.
Abuse
The other kind of 403 errors it received had another error message
You have triggered an abuse detection mechanism and have been temporarily blocked from content creation. Please retry your request again later.At first, we wondered: how an application that just executes between 5 to 15 API calls per GitHub events could trigger this?
It turns out that GitHub has an understated documentation item about their abuse protection behavior. Our application was respecting every point, except:
Make requests for a single user or client ID serially. Do not make requests for a single user or client ID concurrently.
Right. In theory, our Celery worker-based approach was able to run things in parallel. However, in practice, it was quite unlikely that many HTTP calls for the same organization would have happened in parallel.
Still, the number of errors we received was growing with time, and the number of Mergify users never shrinks.
At this point, we knew that our system needed to be redesigned a bit.
Redis Stream to the Rescue
To solve those two concerns, we had to reduce the number of API calls done to GitHub and be sure we never had more than one API request to execute at the same time. We also had to keep a retry mechanism as we had with Celery — in case of unexpected issues.
The indisputable choice was to evaluate multiple tasks in a single batch to reduce the number of API calls. Unfortunately for us, Celery doesn't offer this feature on top of the Redis Pub/Sub mechanism. Furthermore, that would not have resolved the abuse problem.
These days, there is a lot of choices to process continuous flows of data. Kafka Streams or Amazon Kinesis usually provide an excellent replacement to a classic Pub/Sub messaging system.
Streams are a good match in our case. The engine can create one stream per organization and ensure that only one worker processes a particular stream at a time. It then can retrieve multiple events at the same time to batch them.
However, software like Kafka is a big beast, and we don't want to manage such a massive tool ourselves. Managed Kafka instances can also be quite expensive. On the other hand, Amazon Kinesis looks reliable and cheap, but your application becomes locked with Amazon and not-so-cheap-anymore when you grow or want more retention.
Therefore, we looked for a streaming API that would match our criteria of being simple to use and cheap. We found out Redis was a perfect match. Redis is easy to deploy, and managed instances are inexpensive and readily available.
Since version 5 released last year, Redis has a new, easy to use and performant stream API. At Mergify, we were already using Redis for caching, queue events, and handling our merge queue. Building on top of the existing infrastructure is a big win for us, as it implies little to no additional cost.
In the end, Mergify engine has been reworked to follow the following architecture:
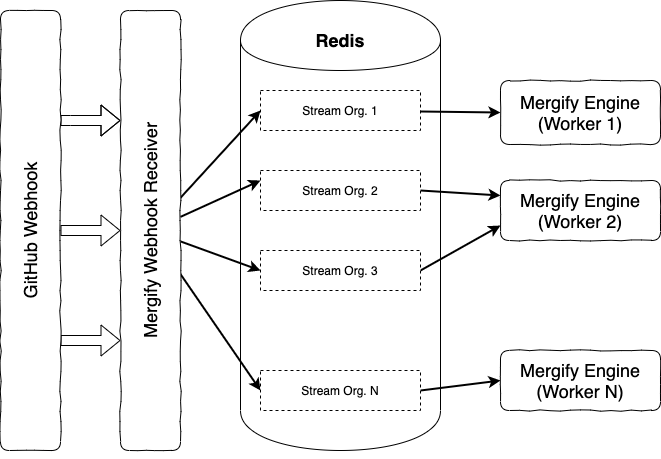
Every event is dispatched in its own organization stream, and a particular stream is consumed by only one worker. This makes it easy to scale the workload by creating new streams, spawning more workers, and even sharding data across several Redis instances.
The stream messages are only acknowledged if everything runs smoothly. In case of a GitHub incident or a bug, the messages are kept and retried later.
Today
After the replacement of Celery by some custom code to write and read GitHub events into Redis Streams, we were able to handle the load without reaching any rate limit or abuse anymore.
We globally reduced the number of GitHub API calls by 4, and even by 20 for large organizations — with no additional cost.
We grew the number of events we handled every day by a factor of 10 over the last year. We feel we are now ready to ingest millions more of GitHub events, thanks to Redis Streams.

