
Converting a Python application to asyncio
As you may know, the Mergify engine is written in Python. To execute its vast number of asynchronous tasks, it was leveraging Celery, a framework providing task queues. While Celery is a prominent framework, it was not suited anymore for Mergify growth. In 2020, we decided to replace Celery with Redis Streams and built a custom solution. Celery was the last dependency the engine was heavily relying on, which was not supporting asyncio — the asynchronous library for Python.
Switching away from Celery allowed us to move our engine to be fully asynchronous. However, migrating the entire application in one shot was not an option, so we had to establish a plan.
Why switching to asyncio?
An application has limited choices when it comes to running things concurrently. You could use threads, multiple processes, or an event-based loop. Other languages than Python sometimes provide other abstraction, such as Go's goroutine.
Using Celery, we had easy access to its multi-process, which spawns several Python processes to parallelize the tasks to execute.
As with many applications nowadays, the Mergify engine is I/O heavy: it receives events, stores them in Redis, reread them, and does many GitHub API calls to evaluate your rules and run your actions.
Using the multi-process approach worked well; each time a task was doing an I/O, other processes could run another job in parallel. The downside of that approach is that the more you want to do in parallel, the more you have to spawn processes. A process is almost a complete clone of your application, so it demands a lot of memory. In our case, that'd be around 64 MB of memory per process, limiting the parallelization of tasks to 16 on a node equipped with 1 GB of memory.
The alternative would have been to use threads or an event-loop to limit the engine to a single process and reduce memory overhead.
While switching to Redis Streams, we replaced Celery's main loop with an asyncio-based event-loop and mixed it with threads to migrate step-by-step. Let's see how we did it!
Where to start?
The first thing to do is to write an event-loop. We used asyncio to replace the Celery processes with asyncio tasks. The main function would start N engine instance as tasks and schedule them. Each engine task would run the heavy work by calling asyncio.to_thread, ensuring the event-loop can schedule all the tasks (await yields back the execution), and assuring the blocking code runs into its own thread.
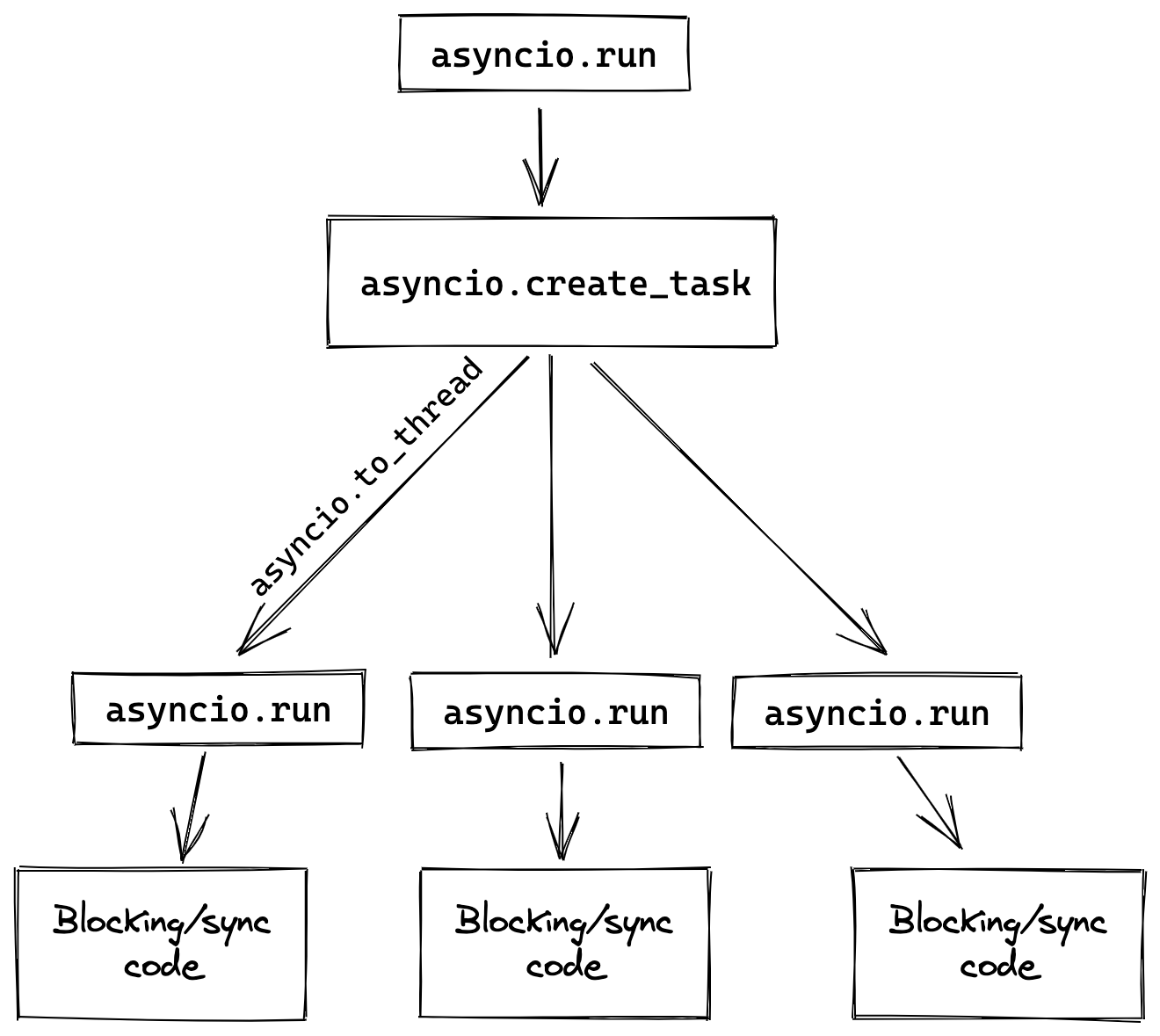
The code would be something like:
async def legacy_blocking_engine_code():
...
def our_sync_async_glue():
asyncio.run(legacy_blocking_engine_code())
async def new_engine():
async for some_events in our_redis_stream.read_a_batch_of_events():
await asyncio.to_thread(our_sync_async_glue)
async def main():
for _ in range(WORKER_NUMBER):
asyncio.create_task(new_engine())
asyncio.run(main())That first step made sure that the core of the engine was completely async. The coroutine our_legacy_blocking_engine_code() is not async and can block, but it does not preclude the other engine's tasks since it runs in its own thread.
Convert all the code!
Now that the chore is async, the rest of the job is to convert all the internals to be async. Converting code is not the most fun, but it's pretty straightforward.
We ditched our old-world libraries, such as redis-py and requests, and replaced them with fancy new async aredis and httpx. As httpx supports a synchronous mode, it was even possible for us to start the httpx migration early on without bothering with the async approach.
Slowly but surely, we rewrote every def function with their async def equivalent, leveraging the asynchronous method of the I/O libraries. If we needed a bridge between a synchronous operation and an asynchronous one, we would run the async def with asyncio.run.
async def update_foobar(ctxt):
data = await ctxt.async_redis.get("my-data")
...
ctxt.sync_http.post("https://api.github.com/repos/....", json=payload)
...
await ctxt.async_redis.set("my-data", updated, nx=True)
Once converted, the code would become:
async def update_foobar(ctxt):
data = await ctxt.async_redis.get("my-data")
...
await ctxt.async_http.post("https://api.github.com/repos/....", json=payload)
...
await ctxt.async_redis.set("my-data", updated, nx=True)On the non-technical side, we enforced a code review policy that mandated using asynchronous code for any new feature. That made sure we were going in the right direction and that we were not adding more and more technical debt as the project grew.
The end
Finally, once we converted every function, we pushed the last change removing the remaining blocking code and dropping the remains of the blocking Redis and HTTP clients.
As we were confident that all our code was async, there was no more reason to use threads to parallelize engine workers. With such a simple change, we removed the threads and moved all the tasks into the same event-loop.

The code change would look like this:
--- sync-async.py
+++ async.py
@@ -1,10 +1,13 @@
- async def our_fully_migrated_async_engine_code():
+ async def our_legacy_blocking_engine_code():
...
+ def our_sync_async_glue():
+ async.run(our_legacy_blocking_engine_code())
+
async def new_engine():
async for some_events in redis.read_a_batch_of_events():
- await our_fully_migrated_async_engine_code()
+ await asyncio.to_thread(our_sync_async_glue)
async def main():
for _ in range(WORKER_NUMBER):Did it work?
To make sure that everything went smooth, we added metrics to various parts of our engine. Our primary metric is measuring the engine latency, i.e., the time needed to start the treatment of new events.
If this number increased, it would have meant that something was blocking the execution, preventing scheduling of other worker's tasks.
Everything turned out well in our case, and we only saw improvement in all our metrics. We're now able to run up to 50 concurrent workers in only 400 MB of memory.
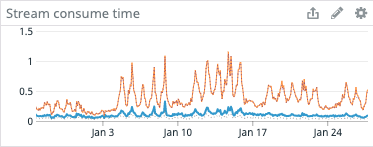
Compared to the original Celery-based architecture, this is a 7x improvement in memory usage, making it easier for Mergify to scale up as it grows.

