
Behind the scene of time-based conditions
Last month, we announced a new set of conditions for Mergify rules based on time. You can now use a time and date and compare pull request attributes to dates and times.
We had the idea for this feature since the beginning of Mergify, but we delayed it for a long time because of the envisioned complexity of getting it right. Our engineering philosophy is always to get things right, and then optimize — rather than the other way around.
As it turns out, the implementation of this functionality was challenging and full of traps. Here's how we did it.
How Mergify evaluate your conditions
The overall workflow of Mergify is quite simple: Mergify's engine stores each event sent by GitHub in a Redis stream. Then, dedicated workers read batches of events from the stream and evaluate your pull requests rules.
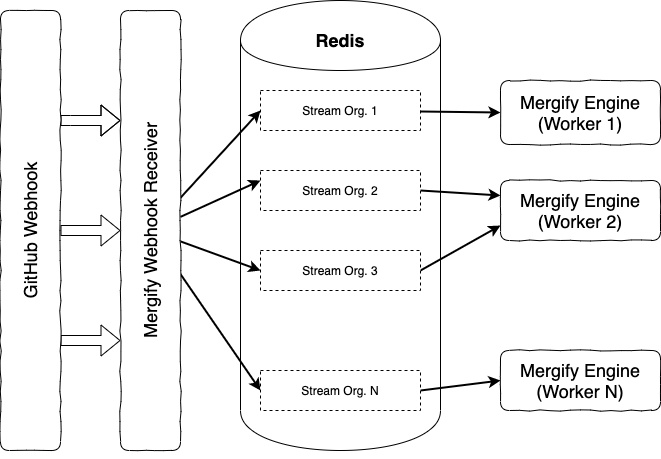
For time-based conditions, the system differs: there's no natural event to trigger pull request evaluation.
Indeed, Mergify needs to evaluate the pull requests rules automatically when the timestamp written in a configuration is reached. If a condition says current-time>=10:00 and it's currently 9 am, Mergify must re-evaluate the pull request situation at 10 am.
The problem is that GitHub has no reason to send an event at 10 am to trigger Mergify. So how do you solve that? 🤔
Naive Approaches
Our first idea was to look at how all other GitHub Apps or Actions solve this issue.
For example, Stale Probot evaluates the state of the pull requests every hour and does this 30 pull requests by 30 pull requests. Ok, that could work for Mergify, except that:
- the latency can be very high
- if you have more than
30 PRs × 24 hours = 720 pull requeststhis does not work anymore.
Right, so that's not scalable.

In the Close Stale GitHub Action, the implementation is quite similar. The action is triggered when GitHub triggers a on scheduleevent. Their recommendation is to evaluate all pull requests once a day and to limit to 1000 pull requests.
Again, not scalable.
Those are just two examples, but it sums up the state of the art around time-based pull request evaluation: periodical query the GitHub API to know if a pull request timestamp attribute changes.
The design choices made in those cases make sense. Sure, the latency can be very high, but if your goal is to only close stale pull requests, having a high latency is not a big deal.
Limiting the number of pull requests also makes sense. Evaluating a pull request requires a ton of queries to GitHub, by doing so too often, you have a good chance to reach the GitHub API calls quota. In the case of a GitHub Action-based solution, it would drain your CI minutes plan and cost you a lot of money.
In Mergify's case, the goal is not only to close stale issues but also to trigger, e.g., a merge as soon as your office hours start. This means the action must run sharply at the scheduled time.
Therefore, does our engine really need to evaluate every pull request every N minutes? No. It just needs to know when to re-evaluate a pull request.
Thinking at Scale
To bear with those limitations, we drafted a different mechanism that would work with a large number of pull requests while providing low latency.
The idea is to maintain a calendar of when a pull request should be evaluated (again). To do this, you need to compute the next timestamp of when a pull request must be checked again, updating this timestamp each time Mergify evaluate the conditions.
Doing this for every pull requests provides Mergify a complete time table which indicates when to schedule its evaluation work for each pull request, without having to wake up randomly every N minutes.

Computing Time
To fill this calendar, the first step is to be able to compute the next time a pull request conditions might change due to the time. If you take the following example and evaluate it at 9 am, I'll let you guess when you need to schedule another evaluation:
- or:
- and:
- author=alice
- current-time>=10:00
- current-time<=18:00
- and:
- author=bob
- current-time>=14:00
- current-time<=20:00
Too bad: you can't compute the answer if I don't tell you who the author is.
Ok. It's alice.
Pretty easy then: the answer is 10 am. At 10 am the engine must re-evalute this pull request because it's likely something will happen: if the author is still alice, then the condition will become true and the actions will have to be triggered.
If the author has changed in the meantime and became charlie, then the condition will be false and the next time to evaluate is never. If the author became bob, then the next time to evaluate the pull request would become 2 pm.
How you compute this time is quite ingenious — at least we think it is. Read on.
The Time Tree

Mergify rules are evaluated using a filtering syntax tree that we implemented a couple of years ago. This system builds a tree based on the list of conditions, evaluates each node each and returns a Boolean indicating if a pull request matches or not. The result of each node in the tree is also returned so we can provide detailed results to the end user as why the rules match or not.
We decided to reuse this abstract tree to evaluate the time-based conditions: it'd just return a timestamp rather than a Boolean.
All we had to do is to refactor the binary filter tree and abstract it so it becomes more generic. The original code looked like this:
class Filter:
binary_operators = {
"eq": operator.eq,
"gt": operator.gt,
"ge": operator.ge,
"lt": operator.lt,
"le": operator.le,
...
}
def __init__(self, tree: TreeT) -> None:
# Parse the tree and store the evaluator
self._eval = self.build_evaluator(tree)
def __call__(self, value) -> bool:
# Call the evaluator with the value
return self._eval(value)
def build_evaluator(self, tree: TreeT) -> Callable[[value], bool]:
...The new generic version returns a ResultT typevar:
class Filter(typing.Generic[ResultT]):
def __init__(self, tree: TreeT, binary_operators: typing.Dict[str, Callable[[T, T], ResultT]) -> None:
# Parse the tree and store the evaluator
self.binary_operators = binary_operators
self._eval = self.build_evaluator(tree)
def __call__(self, value) -> bool:
# Call the evaluator with the value
return self._eval(value)
def build_evaluator(self, tree: TreeT) -> Callable[[value], ResultT]:
...
def BinaryFilter(tree: TreeT) -> "Filter[bool]":
return Filter[bool](
tree,
{
"eq": operator.eq,
"gt": operator.gt,
"ge": operator.ge,
"lt": operator.lt,
"le": operator.le,
...
}
)
With this abstraction done, it's possible to write a new class NearDatetimeFilter, that will returns the closest timestamp found in the condition.
def NearDatetimeFilter(tree: TreeT) -> "Filter[datetime.datetime]":
return Filter[datetime.datetime](
tree,
{
"eq": _dt_op(operator.eq),
"lt": _dt_op(operator.lt),
"gt": _dt_op(operator.gt),
"le": _dt_op(operator.le),
"ge": _dt_op(operator.ge),
...
},
)
The magic happens in the _dt_op() function. We need the get the next time one of the conditions changes, to property do the reporting (to provide a good report to the user) which is not necessarily the next time all conditions become valid.
Therefore, the code of this method does something along those lines:
- if the attribute is not time-based (e.g., a condition is done on the pull request
title), returnsdatetime.datetime.max - if the attribute is time-based and can't match in the future, returns
datetime.datetime.max(e.g., it's the year 2021 and the condition statescurrent-year<=2020) - if the time-based attribute can match in the future returns when it will match, e.g., it's the year 2019 and the condition states
current-year<=2020, returnsJanuary 1st, 2020 at 00:00.
If you're curious about the details, the implementation is here.
Now that those timestamps are computed each time a pull request is evaluated, they need to be stored for the engine to take action.
Storing Time
Once the timestamps are computed, you need to stash those results. To store this calendar, we decided to leverage Redis, one of our favorite datastore. Redis provides ordered sets; all we had to do is to use the timestamp as a score.
Every minute, Mergify requests Redis the list of pull requests to re-evaluate and triggers a refresh for these pull requests.
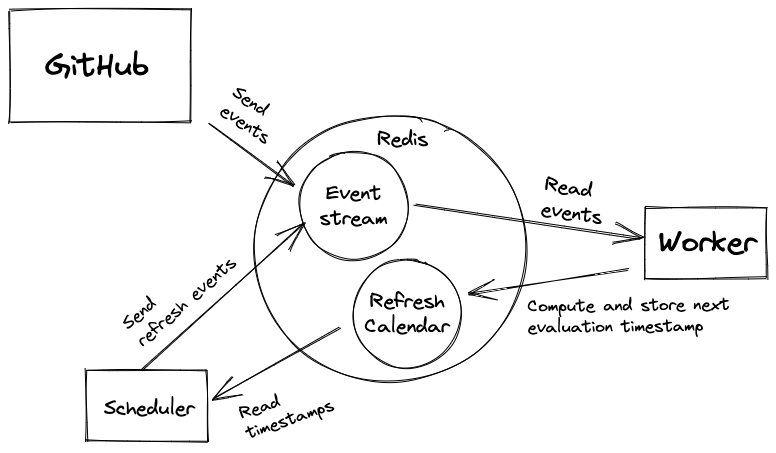
The elegance of this design is that scheduling this refresh event does not need any new GitHub request, since the data was computed when the engine evaluated the pull request in the first place. Quota saved!
As we explained last year, evaluating pull request in batch is a key to having low latency and high throughput while avoiding to hit GitHub API rate limits and quotas.
Some trade-offs
A weakness of this solution is that if your condition relies on current-time or current-day, it will generate a large number of refresh events just after midnight. Indeed, writing current-time<06:00 means "between midnight and 6am", which means the condition might change twice a day. The same applies if you rely on the day number, which changes at midnight.
This turned out to not be a big issues, as Mergify has been built to deal properly and efficiently with the the abuse and rate limit system of GitHub.
We also made the choice to limit the operators that can be used to match timestamps: you can use > or <=, but you can't use equality operators such as = or !=. The system is not precise enough to make sure the condition will be evaluated at, e.g., 10 am sharp.
What's next?
This system has been in production for more than 3 months with great success. The overall number of query we sent to GitHub has not been impacted by the adoption of this new functionality.
This opens a large number of uses case we'll be happy to talk you through in the upcoming weeks. Stay tuned!

